In the previous part I looked at how file processing could benefit from watching directories. In this part I will be looking at introducing file manipulation during the processing. Here I work through processing various text and binary files.
.NET Methods
- File.ReadAllText
- File.WriteAllText
- File.ReadAllLines
- File.WriteAllLines
- File.AppendAllText
- File.AppendAllLines
- File.Move

Reading & Writing Text Files
Once the file has been picked up by the file watcher the file processing begins. In this scenario we have text files that need to have text appended to them. This can happen in a couple of different places. I've edited the solution in the following ways.
Reading Whole Files into Memory
A new class called TextFileProcessor was added. Initially this will have some very basic processing. It will read all the text and append it with a signature. This uses the File.ReadAllText and File.WriteAllText methods. This will read the file at the defined location into memory. Once it's in memory the contents of the file can be modified. The new modified text then gets written to the new location. File processing has been completed at that point. The code below delivers on that behaviour.
public class TextFileProcessor
{
public string FilePath { get; set; }
public string NewFilePath { get; set; }
public string AppendText = $"{Environment.NewLine}{Environment.NewLine}" +
$"Best regards,{Environment.NewLine}{Environment.NewLine}" +
"From Paul";
public TextFileProcessor(string filePath, string newFilePath)
{
FilePath = filePath;
NewFilePath = newFilePath;
}
public void Process()
{
var text = File.ReadAllText(FilePath);
var processedText = text + AppendText;
File.WriteAllText(NewFilePath, processedText);
}
}
In the FileProcessor there has been some modification. The ProcessTextFile Method has been removed. Then the ProcessFile Method has been modified to use the new TextFileProcessor. The file moving behaviour has been replaced with a deletion as the processing will be completely governed by the TextFileProcessor. The file name declarations have been moved up to the top of the method so that they can be used inside the switch statement.
private void ProcessFile(string processingFilePath)
{
var extension = Path.GetExtension(_filePath);
var finishedDir = Path.Combine(_rootPath, FinalDir);
Directory.CreateDirectory(finishedDir);
var finishedFileName = $"{Path.GetFileNameWithoutExtension(_filePath)}-{Guid.NewGuid()}{extension}";
var finishedFilePath = Path.Combine(finishedDir, finishedFileName);
switch (extension)
{
case ".txt":
var textProcessor = new TextFileProcessor(processingFilePath, finishedFilePath);
textProcessor.Process();
break;
default:
WriteLine($"{DateTime.Now.ToLongTimeString()} - {extension} is not a supported file type.");
break;
}
WriteLine($"{DateTime.Now.ToLongTimeString()} - {processingFilePath} has been processed.");
WriteLine($"Removing {processingFilePath}");
File.Delete(processingFilePath);
}
The draw back to this approach is that it has a bigger memory footprint which can have consequences down the line. It is more efficient to read lines into memory rather than entire files.
Reading Lines into Memory
To read lines into memory rather than the entire file we just need to use the File.ReadAllLines and File.WriteAllLines methods instead.
This is done in the TextFileProcessor. I changed the property being appended to a list of strings. The file gets read into memory line by line. Once we have the list the values get appended to the list. It then writes to the new location line by line.
public class TextFileProcessor
{
public string FilePath { get; set; }
public string NewFilePath { get; set; }
public List<string> AppendList = new List<string>
{
string.Empty,
string.Empty,
"Best regards,",
string.Empty,
"From Paul"
};
public TextFileProcessor(string filePath, string newFilePath)
{
FilePath = filePath;
NewFilePath = newFilePath;
}
public void Process()
{
var lineList = File.ReadAllLines(FilePath).ToList();
lineList.AddRange(AppendList);
var lines = lineList.ToArray();
File.WriteAllLines(NewFilePath, lines);
}
}
The benefit of this approach is that the entire file isn't read into memory all at once. This helps us get around issues around file size issues. We don't have to have the entire file in memory all at once we can read and write it in segments. The one draw back of this is that at some point an additional line is added. This would need to be mitigated at some point.
Appending Text
There's another more advisable way to append content and it's with the use of the File.AppendAllText and File.AppendAllLines methods. The below two examples would be able to replace the above Process method examples.
File.Move(FilePath, NewFilePath);
File.AppendAllText(NewFilePath, AppendText);
File.Move(FilePath, NewFilePath);
File.AppendAllLines(NewFilePath, AppendList);
Encoding
All of the read and write methods have an encoding parameter option. This is a class with the following encoding options.
- ASCII
- UTF8
- UTF7
- UTF32 (little endian)
- Unicode (UTF-16 little endian)
- BigEndianUnicode (UTF-16 big endian)
The endianness referred here denotes whether the byter order is biggest or littlest first. Typically text files will be UTF8 which doesn't have a byte order mark. There are situations in which using different encodings is required. But in this I'm just using standard UTF-8 encoding.
ASCII is single byte character data (8 bit encoding) which is not affected by endianness. The bytes are stored in the same order always, so if you needed access to the third character in a string, you just need to access the third byte. ASCII only has 256 characters available to it with very few symbols.
Unicode is multi byte character data (7-32 bit encoding) which has various endianness. The first 128 character of unicode map to the first 128 characters of ASCII so in that regard they can be interchangeable. However due to the variety of encoding, characters aren't always read in the same way as ASCII. In UTF-8 for instance (which is the closest to ASCII), there are checks in place. If you needed to access the third character in a string, you first need to identify the first character to see if it is a one or a multi byte character (utf-8 characters can use between 1 and 4 bytes each). Then you need to do the same for the second character and then you are able to access the third character. So there are performance implications here to consider at scale. UTF-8 is capable of having 1,112,064 characters available to it. This is a concern mostly attributed to database schemas when deciding what types are needed.
Here is an article I read for more background on this.
Reading & Writing Binary Files
The reading and writing of text files will likely have more utility than writing binary in most basic cases. However on your computer there is more binary files than text, so there will be plenty of scenarios that entail having to read and write to a binary file.
But here is how you can do it in a basic rudimentary way. I added a new class called BinaryFileProcessor in the same way that TextFileProcessor was setup.
public class BinaryFileProcessor
{
public string FilePath { get; set; }
public string NewFilePath { get; set; }
public BinaryFileProcessor(string filePath, string newFilePath)
{
FilePath = filePath;
NewFilePath = newFilePath;
}
public void Process()
{
// binary process code will be here shortly
}
}
The ProcessFile method was modified in the FileProcessor class. The BinaryFileProcessor use was added to the switch statement.
switch (extension)
{
case ".txt":
var textProcessor = new TextFileProcessor(processingFilePath, finishedFilePath);
textProcessor.Process();
break;
case ".bin":
var binaryProcessor = new BinaryFileProcessor(processingFilePath, finishedFilePath);
binaryProcessor.Process();
break;
default:
WriteLine($"{DateTime.Now.ToLongTimeString()} - {extension} is not a supported file type.");
break;
}
In the BinaryFileProcessor I added some code in the Process method to find largest byte and add that byte again at the end. Not exactly a real life use case, but let's just keep things simple. This works as an example for using the File.ReadAllBytes and File.WriteAllBytes methods.
public void Process()
{
var data = File.ReadAllBytes(FilePath);
var largest = data.Max();
var newData = new byte[data.Length + 1];
Array.Copy(data, newData, data.Length);
newData[newData.Length - 1] = largest;
File.WriteAllBytes(NewFilePath, newData);
}
Making the binary file to process
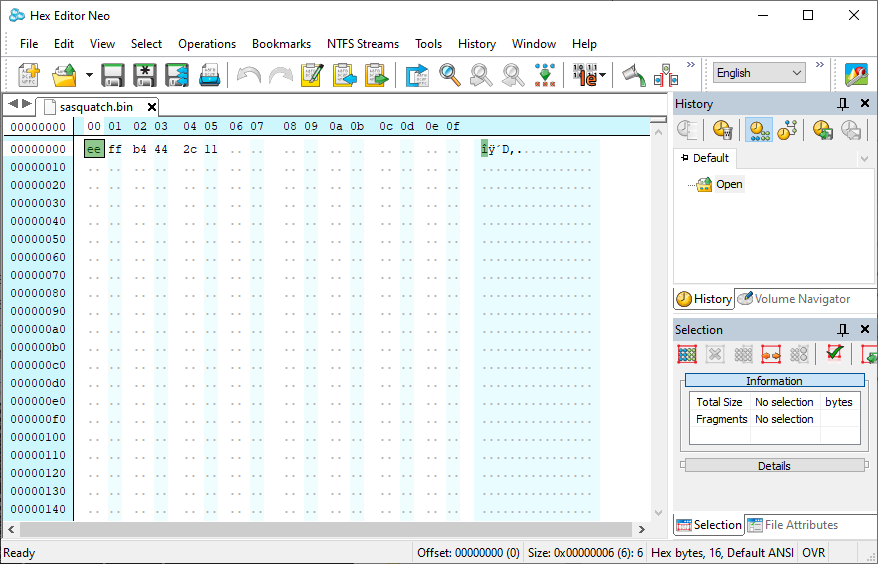
A binary file isn't as straight forward to observe like a text file. You can open up a text file before and after in a text editor to see changes. For a binary file You can use Powershell to see these changes. The command that I used is Format-Hex –Path “path”.
But to edit the file to use as test data it's preferred to use a hex editor. I created a binary file by running this command fsutil file createnew sasquatch.bin 5. This creates a binary file with a data length of 5 bytes. This doesn't have any data in it really, it needs to modified. Now that I have a binary file I edited it using HHD Hex Editor Neo (free edition). I just entered random data into the file (I probably could have just created a new bin file through HHD Hex editor also).
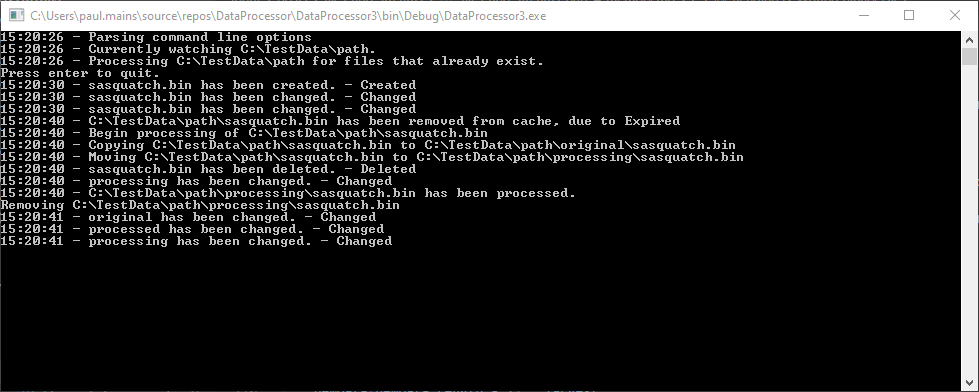
Running the process
The next step is to run the console application and drop the new bin file into the watched directory.
Once that has been done the binary file can be opened up. It should be noticed that the largest byte has been appended to the end of the file.
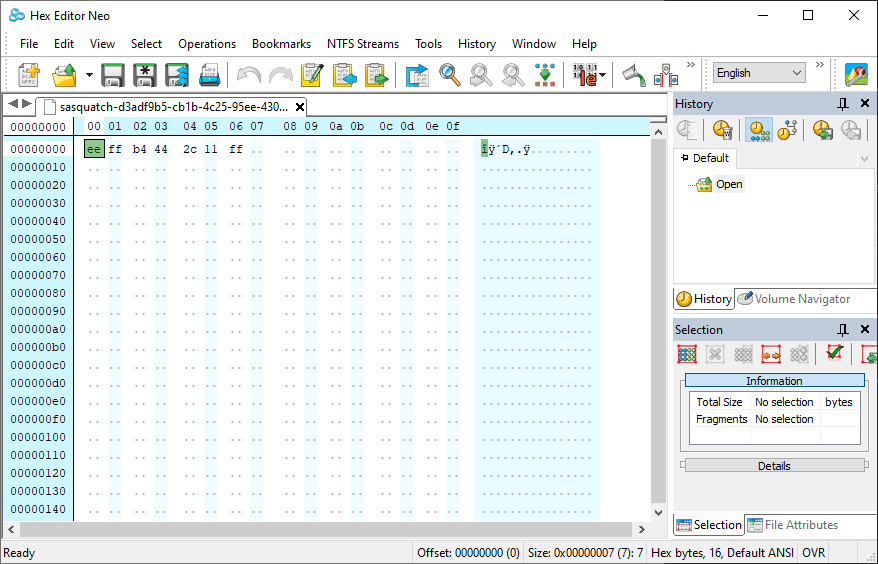
Why someone might need to do this? Who knows? But it is a basic example of being able to programmatically alter binary files.
Summary
| Pros | Cons |
|---|---|
| Simple logic | Slow processing |
| Simple to write | Not scalable (will crash if file too large) |
| Simple to maintain | No random access / seeking |
Here we went through file manipulation techniques, expanding on previous parts. It's very simple to append text and binary. It's also good to have some degree of an understanding around encoding. It will save you in many situations.
In the next part I talk about streams or memory mapped files... I haven't decided yet.
Good night!
