The previous part was about how to manage files and directories. In this part, I essentially refactor the application to operate by watching the files and directories for changes rather than running the file processing a single time. The result of the monitoring will trigger the processing whenever a change event is raised.
.NET Methods
- Directory.Exists
- Directory.EnumerateFiles
- File.Exists
- ConcurrentDictionary.TryAdd
- ConcurrentDictionary.TryRemove
- TimeSpan.FromSeconds
- Console.WriteLine
- Console.Read
- MemoryCache.Add
- String.IsNullOrEmpty

Let's do this!
FileSystemWatcher

The FileSystemWatcher class when instantiated and set to raise events (by setting EnableRaisingEvents to true). This will watch a specified directory like a hawk. The properties available to change are the following (I've crossed out the properties that I didn't use).
Properties
- EnableRaisingEvents
- Filter
- Path
- InternalBufferSize
- NotifyFilter
- IncludeSubdirectories
SiteSynchronizingObject
Initial Implementation
Initially the program processed files sequentially based on when the event is raised. This can present quite a few problems and is too rudimentary of a solution to be scalable. It will use the default buffer size and default filter (i.e everything).
private static void Main(string[] args)
{
WriteLine("Parsing command line options");
var directory = args[0];
if (Directory.Exists(directory))
{
WriteLine($"Currently watching {directory}.");
using (var fileWatcher = new FileSystemWatcher(directory))
{
fileWatcher.IncludeSubdirectories = false;
fileWatcher.Created += FileCreated;
fileWatcher.Changed += FileChanged;
fileWatcher.Deleted += FileDeleted;
fileWatcher.Renamed += FileRenamed;
fileWatcher.Error += WatcherError;
fileWatcher.EnableRaisingEvents = true;
WriteLine("Press enter to quit.");
Read();
}
}
else
{
WriteLine($"Error: {directory} doesn't exist.");
}
}
Multiple events being monitored to track file manipulations to then perform file manipulations on files within the monitored directory can be a recipe for disaster if not handled correctly... and somewhat of a mouth full to say.

Event Mappings
Behaviour was mapped against the following events. The operating system will alert the FileSystemWatcher buffer of these changes. The code was setup to only process files on file creation and file change.
Once a change event has been raised it will report the change type and perform the file processing on create and change.
private static void FileCreated(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been created. - {e.ChangeType}");
var fileProcessor = new FileProcessor(e.FullPath);
fileProcessor.Process();
}
private static void FileChanged(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been changed. - {e.ChangeType}");
var fileProcessor = new FileProcessor(e.FullPath);
fileProcessor.Process();
}
private static void FileDeleted(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been deleted. - {e.ChangeType}");
}
private static void FileRenamed(object sender, RenamedEventArgs e)
{
WriteLine($"{e.OldName} has been renamed to {e.Name}. - {e.ChangeType}");
}
private static void WatcherError(object sender, ErrorEventArgs e)
{
WriteLine($"Error: File watcher has exploded. Exception: {e.GetException()}");
}
When running this application it is very noticeable that there is a flurry of activity, as events hit the buffer. The issue is that there is just too much being raised. You would not describe the frequency of file processing to be efficient. To remedy this the program is in dire need of some filtering.

Filtering
To make the file processing occur only when it is needed, the use of the NotifyFilter property is needed. We will just need to pay attention to the creation of the file or whether the file name or last write is the cause of the change.
| NotifyFilters Fields | ||
|---|---|---|
| Attributes | 4 | The attributes of the file or folder. |
| CreationTime | 64 | The time the file or folder was created. |
| DirectoryName | 2 | The name of the directory. |
| FileName | 1 | The name of the file. |
| LastAccess | 32 | The date the file or folder was last opened. |
| LastWrite | 16 | The date the file or folder last had anything written to it. |
| Security | 256 | The security settings of the file or folder. |
| Size | 8 | The size of the file or folder. |
In addition of adding a notify filter the InternalBufferSize and the Filter properties were modified. The buffer size has been increased to 64kb and the filter was setup to only watch text files. The buffer is likely far too big, but I was just testing to see if I could see any obvious implications. It should be noted that the buffer size has some restrictions to acknowledge. It is not to be larger than 64kb and no smaller than 4kb. It is best for the buffer size to be a multiple of 4. Increasing the buffer size is expensive due to it being non-paged memory that will not be swapped out to disk. It is best to keep the buffer as small as possible. A way to ensure this is the use of notification filters.
private static void Main(string[] args)
{
WriteLine("Parsing command line options");
var directory = args[0];
if (Directory.Exists(directory))
{
WriteLine($"Currently watching {directory}.");
using (var fileWatcher = new FileSystemWatcher(directory))
{
fileWatcher.IncludeSubdirectories = false;
fileWatcher.InternalBufferSize = 65536; // 64kb which is the maximum
fileWatcher.Filter = "*.txt";
fileWatcher.NotifyFilter = NotifyFilters.FileName | NotifyFilters.LastWrite;
fileWatcher.Created += FileCreated;
fileWatcher.Changed += FileChanged;
fileWatcher.Deleted += FileDeleted;
fileWatcher.Renamed += FileRenamed;
fileWatcher.Error += WatcherError;
fileWatcher.EnableRaisingEvents = true;
WriteLine("Press enter to quit.");
Read();
}
}
else
{
WriteLine($"Error: {directory} doesn't exist.");
}
}
When running the application now, it can be noticed that there is much less activity.

However this approach is still risky and prone to bugs and can result in file change duplicates if the file changes are too numerous. If only there was a way to restrict the processing to a happen a single time. If only there was a way to have a list of unique files that wasn't added to numerous times by other events.

Concurrency
Use of a concurrent dictionary can help. Even though this is introducing concurrency the files aren't being processed concurrently (this confusion isn't helped by my method naming choices). Only the list of files are being stored concurrently. The processing will still occur sequentially at a determined interval. Two usings were added to the program. The Concurrent namespace is so the ConcurrentDictionary generic is made available. The Threading namespace is used to get access to the Timer class.
using System.Collections.Concurrent;
using System.Threading;
Now that these are available, the _files property is added along with the timer variable. By adding these, the files get processed every 1000 milliseconds. The methods attributed to the "Created" and "Changed" events, were changed to use methods that add to the _files property.
private static ConcurrentDictionary<string, string> _files = new ConcurrentDictionary<string, string>();
private static void Main(string[] args)
{
WriteLine("Parsing command line options");
var directory = args[0];
if (Directory.Exists(directory))
{
WriteLine($"Currently watching {directory}.");
using (var fileWatcher = new FileSystemWatcher(directory))
using(var timer = new Timer(ProcessFilesConcurrently, null, 0, 1000))
{
fileWatcher.IncludeSubdirectories = false;
fileWatcher.InternalBufferSize = 65536; // 64kb which is the maximum
fileWatcher.Filter = "*.txt";
fileWatcher.NotifyFilter = NotifyFilters.FileName | NotifyFilters.LastWrite;
fileWatcher.Created += FileCreatedConcurrently;
fileWatcher.Changed += FileChangedConcurrently;
fileWatcher.Deleted += FileDeleted;
fileWatcher.Renamed += FileRenamed;
fileWatcher.Error += WatcherError;
fileWatcher.EnableRaisingEvents = true;
WriteLine("Press enter to quit.");
Read();
}
}
else
{
WriteLine($"Error: {directory} doesn't exist.");
}
}
Here is where the files are collected. Because it is now using a concurrent dictionary, if the
private static void FileCreatedConcurrently(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been created. - {e.ChangeType}");
_files.TryAdd(e.FullPath, e.FullPath);
}
private static void FileChangedConcurrently(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been changed. - {e.ChangeType}");
_files.TryAdd(e.FullPath, e.FullPath);
}
Here is where the files are processed. It will iterate through the files and attempt to remove from the list before processing the file.
private static void ProcessFilesConcurrently(object stateInfo)
{
foreach (var name in _files.Keys)
{
// underscore means value is discarded
if (!_files.TryRemove(name, out _))
{
continue;
}
var fileProcessor = new FileProcessor(name);
fileProcessor.Process();
}
}
This approach is slightly better than it was previously, as there is less likelihood of inadvertent processing duplications occurring. The watcher may fire more than one change event for the file but the file will only get processed once. However, there is a tiny risk when using the concurrent dictionary alongside a timer. There is a small possibility that the watcher will fire multiple events and the first will be before the timer interval and another will be after. This will result in the file processing occurring twice. It is a tiny problem that would likely become a much bigger issue when scaling up. To lessen this as an issue the timer interval could be extended, but really, that's just wrapping it in tape and running away. If only there as a way to provide a time for each file to wait for changes events to trickle in. It wouldn't even need to be a long time... maybe just a second or two.

If only...
Processing from a cache!
The bugs that occur in the concurrent dictionary can be resolved by using a cache instead. By using a cache, you can specify an expiration on each file being added. There will be a noticeable difference in the output as the cache only checks for expired items every 20 seconds. However, it is the more robust solution. So let's rip that concurrency dictionary and timer out and add some new methods.
To use the MemoryCache class we need to use the Caching namespace.
using System.Runtime.Caching;
The ConcurrentDictionary has been replaced with a MemoryCache. The timer has now been removed. The Main method now sets up the FileSystemWatcher and binds the appropriate events. It doesn't do any processing directly. The new methods were created with this processing behaviour.
private static MemoryCache _files = MemoryCache.Default;
private static void Main(string[] args)
{
WriteLine("Parsing command line options");
var directory = args[0];
if (Directory.Exists(directory))
{
WriteLine($"Currently watching {directory}.");
using (var fileWatcher = new FileSystemWatcher(directory))
{
fileWatcher.IncludeSubdirectories = false;
fileWatcher.InternalBufferSize = 65536; // 64kb which is the maximum
fileWatcher.Filter = "*.txt";
fileWatcher.NotifyFilter = NotifyFilters.FileName | NotifyFilters.LastWrite;
fileWatcher.Created += FileCreatedCaching;
fileWatcher.Changed += FileChangedCaching;
fileWatcher.Deleted += FileDeleted;
fileWatcher.Renamed += FileRenamed;
fileWatcher.Error += WatcherError;
fileWatcher.EnableRaisingEvents = true;
WriteLine("Press enter to quit.");
Read();
}
}
else
{
WriteLine($"Error: {directory} doesn't exist.");
}
}
Two new methods were setup purely to add the file to the cache.
private static void FileCreatedCaching(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been created. - {e.ChangeType}");
AddToCache(e.FullPath);
}
private static void FileChangedCaching(object sender, FileSystemEventArgs e)
{
WriteLine($"{e.Name} has been changed. - {e.ChangeType}");
AddToCache(e.FullPath);
}
The new AddToCache method sets up a new cache item and sets the method to use when the cache item expires. The expiration is set to 2 seconds, (as this is the minimum required). Once the item is added to the cache, it will quickly expire and the MemoryCache will periodically (every 20 seconds) check for expired items. Once an item expires, it will run the ProcessFileFromCache method.
The ProcessFileFromCache method exists to check that the item was removed for the acceptable reason and run the file processor.
private static void AddToCache(string fullPath)
{
var item = new CacheItem(fullPath, fullPath);
var policy = new CacheItemPolicy
{
RemovedCallback = ProcessFileFromCache,
SlidingExpiration = TimeSpan.FromSeconds(2)
};
_files.Add(item, policy);
}
private static void ProcessFileFromCache(CacheEntryRemovedArguments args)
{
WriteLine($"{args.CacheItem.Key} has been removed from cache, due to {args.RemovedReason}");
if (args.RemovedReason == CacheEntryRemovedReason.Expired)
{
var fileProcessor = new FileProcessor(args.CacheItem.Key);
fileProcessor.Process();
}
else
{
WriteLine($"{args.CacheItem.Key} has been removed from cache, due to unknown reason.");
}
}
There was some additional code added to make this work on files that existed prior to the app start. The ProcessingExistingFiles method was set up to enumerate through the existing files using the EnumerateFiles method and add it to the file cache.
private static void Main(string[] args)
{
WriteLine($"{DateTime.Now.ToLongTimeString()} - Parsing command line options");
var directory = args[0];
if (Directory.Exists(directory))
{
WriteLine($"{DateTime.Now.ToLongTimeString()} - Currently watching {directory}.");
ProcessExistingFiles(directory);
private static void ProcessExistingFiles(string directory)
{
WriteLine($"{DateTime.Now.ToLongTimeString()} - Processing {directory} for files that already exist.");
foreach (var path in Directory.EnumerateFiles(directory))
{
WriteLine($"{DateTime.Now.ToLongTimeString()} - Processing {path}.");
AddToCache(path);
}
}
I have went ahead and added timestamps to all of the outputs to illustrate the time it takes. As there will be a noticeable difference. I deleted the contents of the folder and added all of the text files to this before running the application (it has to be this way to avoid an issue that will be cleared up next).
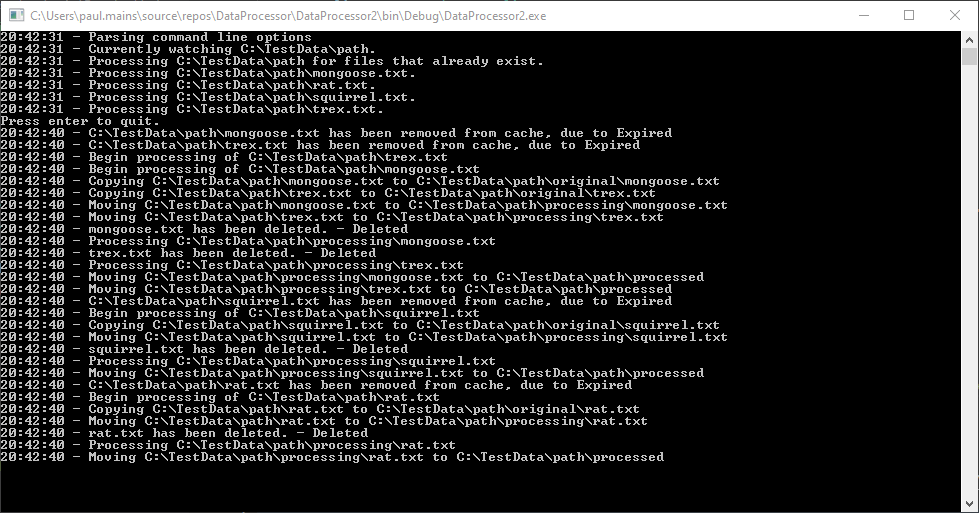
Its clear when the application starts and when the processing occurs (near enough to the 20 seconds that was predicted).
Cleaning up
Issues with missing files
The reason why I had to run the application in that specific way (with the files already existing), was due to an error that happens when adding multiple new files.
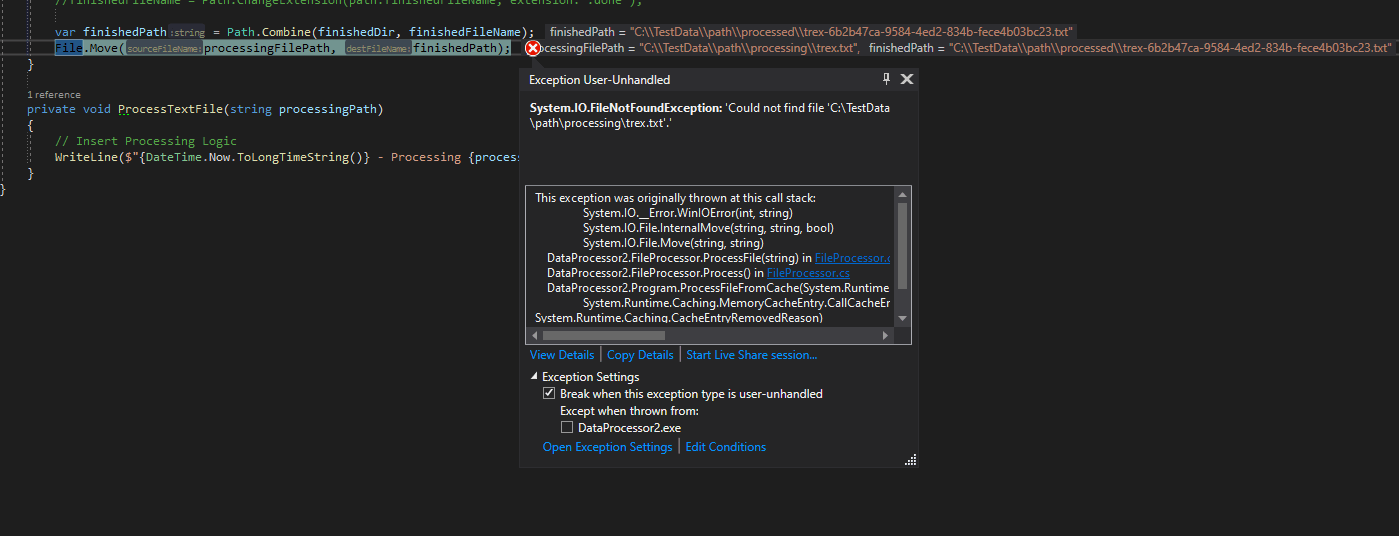
This is due to the processing directory being deleted once the file has been processed. To fix this I just removed that specific functionality in the file processor. Below I just commented that line out.
// FileProcessor.cs
public void Process()
{
WriteLine($"Begin processing of {_filePath}");
// Check if exists using the "Exists" Static Method
if (!File.Exists(_filePath))
{
WriteLine($"Error: {_filePath} does not exist.");
return;
}
BackupOriginal();
var processingFilePath = MoveToProcessing();
if (string.IsNullOrEmpty(processingFilePath))
{
return;
}
ProcessFile(processingFilePath);
// Need to stop the deleting of the processing folder
//RemoveProcessing(processingFilePath);
}
Now it should work.

Summary
This post has gone through the process of changing the application produced in Part 2 into an application that watches a directory for changes. There was an attempt to use a Timer alongside a ConcurrentDictionary, but that wasn't sufficient. It was then changed to use a MemoryCache. This may not be the conventional way to use the MemoryCache. But the expiration callback behaviour is useful in the current context.
In the next Part, I'll expand on reading files into memory, as it will be quite useful if the file processing actually did something with the files.
But for now.

I'm done...